上一篇写AI绘画AI绘画很酷,可是…原理是什么?时,Stable Diffusion尚未发布。文末的原理介绍其实是关于Disco Diffusion。本文想从这两个模型背后的原理层面来比较二者,同时回答(也是回答自己):为什么Stable Diffusion可以这么快?
Disco Diffusion单张耗时在5-10min,Stable Diffusion则只需要5-10s。
一.原理复习
Diffusion模型的作用是将图像"降噪",也就是说它只是实现将一张带有噪点的图像变清晰这个功能。AI能够绘画,依托于模型将用户的输入文本变成能与图像比较的向量,例如CLIP。
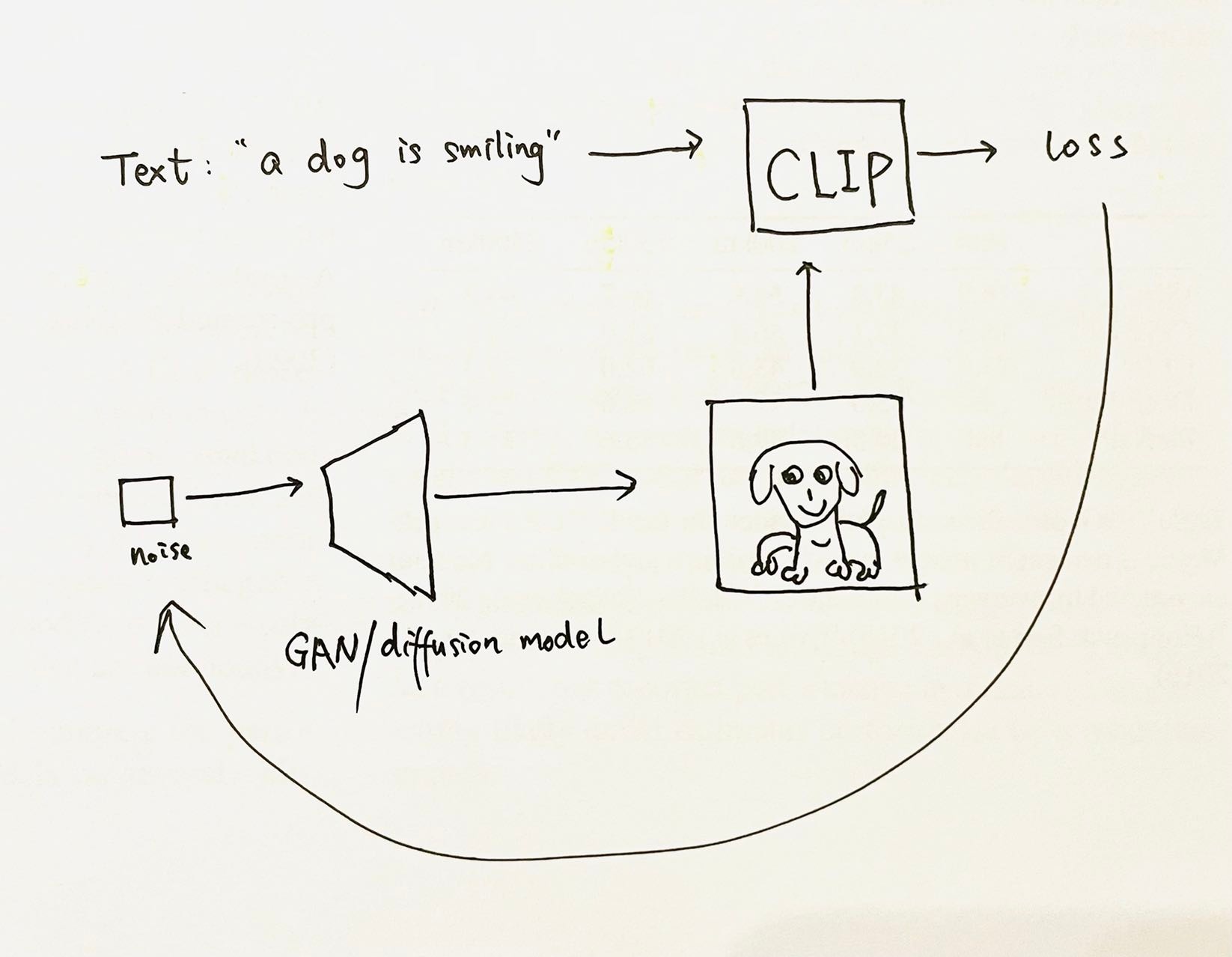
Disco Diffusion就是通过不断将用户的文本(Text)输入,与Diffusion生成的图像计算CLIP损失,一步步实现AI绘画的功能,但是这个迭代过程实在是太太太太慢了。
原因在于:
对于用户指定尺寸的一张分辨率为1920x1080图像,模型每次都要迭代这张图上一共3x1920x1080个像素点的值,并且将这个过程循环240次(steps)。
有没有更好的办法呢?今年年初,几位科学家提出的Latent Diffusion模型,就试图尝试将Diffusion过程放在隐空间(latent)上做,我上一篇文章也有关于隐空间的介绍。
二.在隐空间上做Diffusion
首先,一张图片的隐空间(latent)怎么得到呢?最简单的方法就是训练一个Encoder-Decoder网络,比如下面这个模型:它的输入是一张512x512的图像,模型的Encoder将这张图像变成一个64x64的latent,经过Decoder将其还原成原始的512x512图像。
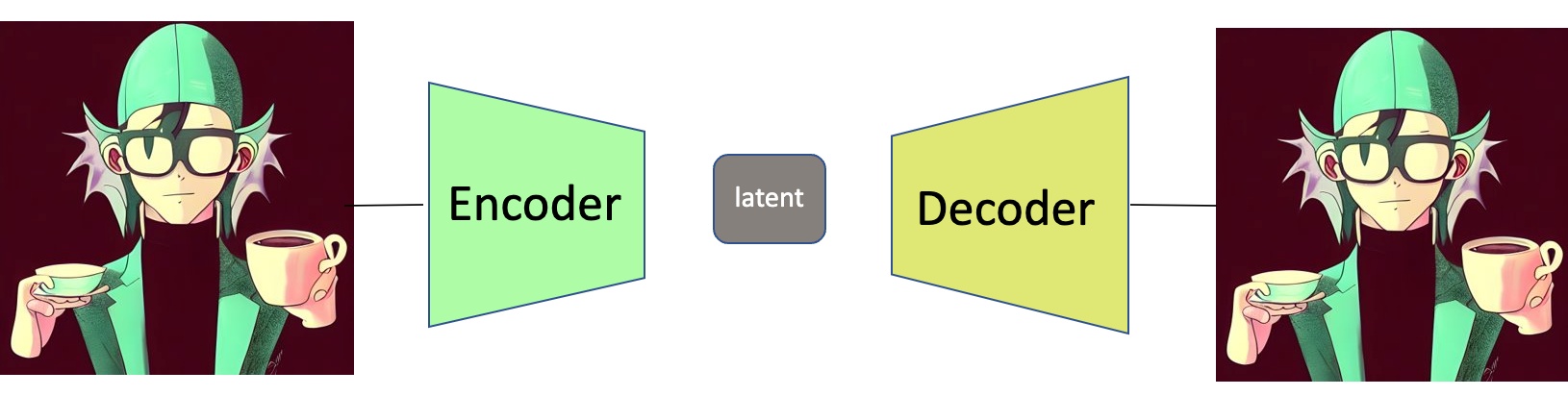
听起来这个模型很蠢,好像什么事也没干。但假如我们保存这个latent(即64x64尺寸的向量),那么哪天原图丢失,模型也可以用latent+Decoder还原这张512x512的图像。而这个latent所花费的存储开支是原图的:
64x64 / 512x512 = 1/64。
简化起见这里不考虑通道数,即认为图像的RGB通道等同于网络的channel数,下同。
因此可以这么理解:
隐空间(latent)包含了一张图像最重要的信息,算是某种意义上的极限压缩。
Latent Diffusion的思路是:把降噪(diffusion)过程在latent层面上做。换句话说,diffusion模型的每次迭代并不是在原始图像上进行,而是每次试图将模糊的latent变得更清晰。
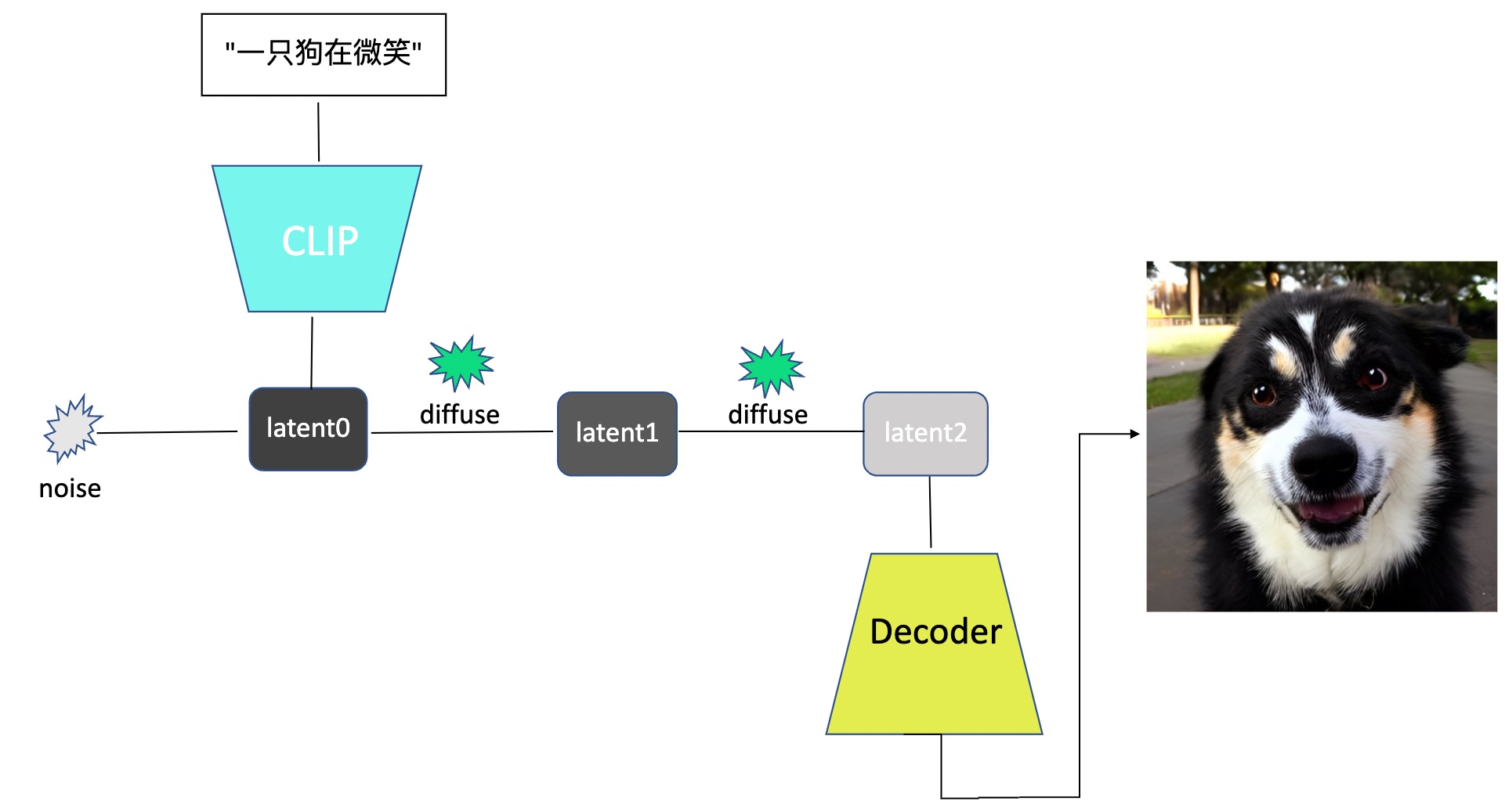
仿照介绍disco diffusion原理时的手稿,这次用PPT做了个latent diffusion思路流程图,如下所示:
- 用户的输入(如"一只狗在微笑")会经过文本编码(Text Embedding)模型变成向量,这里使用的是CLIP。这个向量会与随机产生的噪声noise一起作为最初的隐变量latent0。
- diffusion模型仍然做降噪,但这次只对latent做而不是真实图像,假设latent尺寸是64x64。经过两次(steps=2)降噪(diffuse)后,得到最终的隐变量(latent2),将其通过上文提到的Decoder,就得到了最终512x512的图像输出。
三.为何Stable Diffusion这么快
Stable Diffusion是基于latent diffusion这篇论文,在大规模数据上训练得到的模型,因此可以假定它的模型速度与latent diffusion接近,至少在一个数量级。
因为diffusion是在latent层面做,模型需要处理的数据与disco diffusion完全不在一个量级。以一张512x512的图像为例:
对于Disco Diffusion模型,图像上所有的像素点均由模型生成并迭代,要处理的像素数量512 x 512 ,而对于Stable Diffusion而言,它要处理的latent尺寸是64x64。
即便两个模型处理速度一样快,它们分别迭代完各自的结果,前者所花费的时间大约是后者的:
512x512 / 64x64 = 64 倍。
这解释了为何Disco Diffusion普遍需要几分钟,而Stable Diffusion仅需10秒。
更新: 朋友也提了一点,正如上图所示,Stable Diffusion没有反向回传loss的过程。这也是它更快的一个重要原因。
要说这么快有什么坏处,那可能是64x64尺寸的latent所包含的信息量太过于有限,因此生成内容很难做到精细,常常只有轮廓而缺失细节。许多使用者发现,Stable Diffusion有点缺乏想象力,生成的东西太过于正常,不如Disco Diffusion天马行空。
当然,这也许不是一件坏事。stability.ai选择将代码开源,并且几乎不保留地放出模型,值得敬佩。也许这个行动能真正让AI绘画给普通人带来帮助。
文中人脸、狗均为我用6pen.art的Stable Diffusion模型生成。