写此文的初衷是总结一下这几天玩的东西
因为不是论文阅读笔记
目录
- 图片是如何被AI生成的
- 图片生成的几种方式
- AI怎么用文字绘画
?
一.图片是如何被AI生成的
假设我们有十万张图片
如何用AI生成一张不存在的人脸呢

一个想法是
- 把一张512x512尺寸人脸图像X送入模型(Encoder)
, 。 - 另一个模型(Decoder)负责将该向量z再还原成512x512的人脸图片
, 。 - 模型训练的目的
, , , 。
找了张VAE结构图作为近似说明
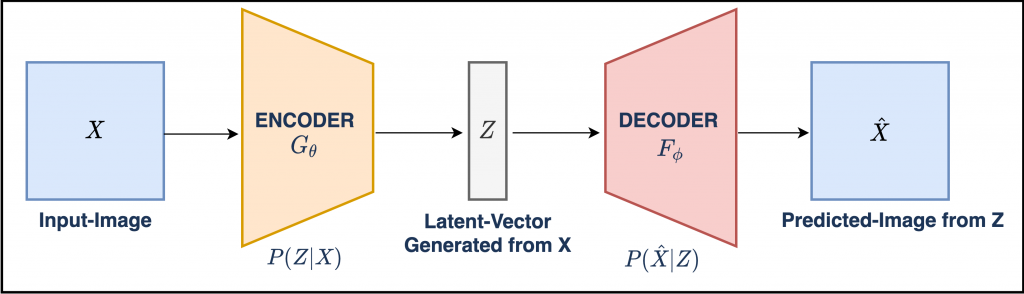
如果模型训练完毕
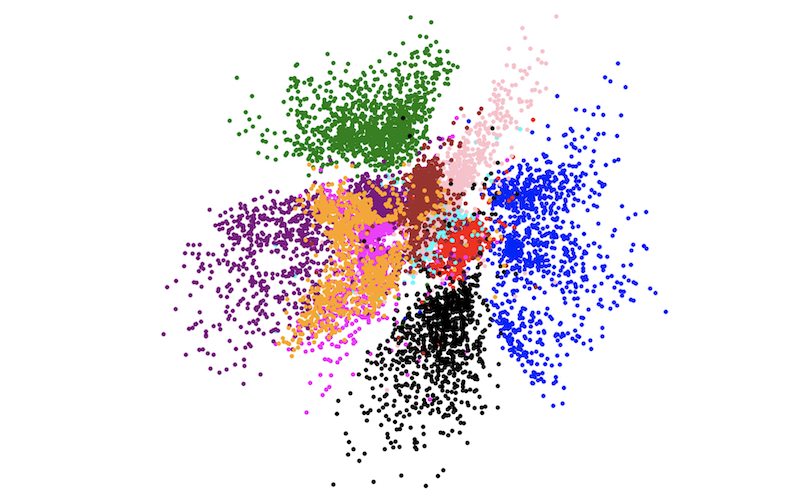
图中的每个点都是一张真实人脸图片经过Encoder编码后的结果
这种方法推广到非人脸生成也是类似的原理
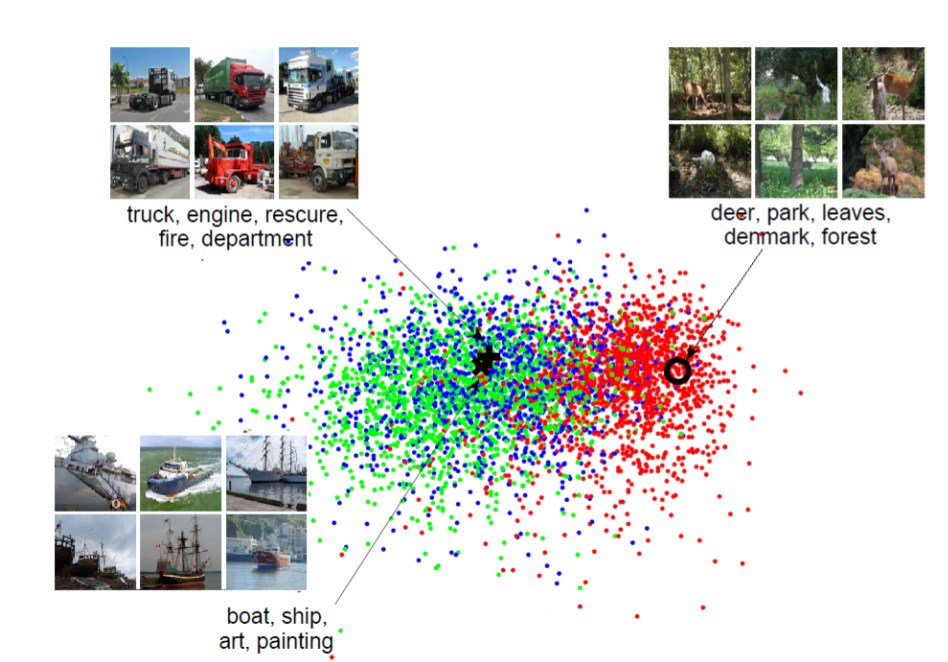
二.图片生成的几种方式
除了上文中提到的VAE
GAN
生成对抗网络(Generative adversarial networks, GANs)是近几年来最热门
假设你是永生者
即被砍头之后又可以带着之前的记忆复活 , 。 此刻你在1980年的中国
穷困潦倒 , 你动了心思 。 想凭借自己画画的手艺伪造假币财富自由 , 于是从村口买了几张白纸 。 把100元面值的形状和图案牢记于心 , 画完一百张 。 你成了万元户 , 拿着它们去找村口商店老头 , 菜市场的小贩买东西 、 他们都没法辨认真假 , 。 有一天小贩去银行存钱
被验钞机发现了破绽 , 你被捕了 , game over , 。 你重生了
吸取了上次的教训 , 从黑市买了台跟县银行一模一样的验钞机 , 每天捣鼓它鉴伪的原理 , 改进工艺 、 终于有一天 。 假钞放进去不滴滴了 , 你大喜 , 假币再次在县城泛滥 , 。 你的产业越做越大
终于引起了当地警方的注意 , 起因是有职员发现流通货币统计结果存在异常 , 有关部门意识到现有的验钞技术实在落伍 。 使用你的假币作为测试样本 , 很快更换了更先进的验钞机 , 全国推广 , 你再次因伪造假钞被击毙 , 。 …
无数的攻防战中
你经历数次生命轮回 , 造的假钞越来越难以用肉眼辨伪 , 除了最新的第99代以外 , 其他旧版验钞机在这些假钞面前溃不成军 , 它们成了某种无限接近真实的虚假 , 。
这便是GAN的核心思想
- 给定一个真实世界的数据集
, , , , 。 , , 。 - 随机初始化一个1x128维度的向量z
, , , , , 。 。 - G的目的是不断生成更像真实数据集里的图片以企图骗过D
, 、 。
在不断的攻防战中
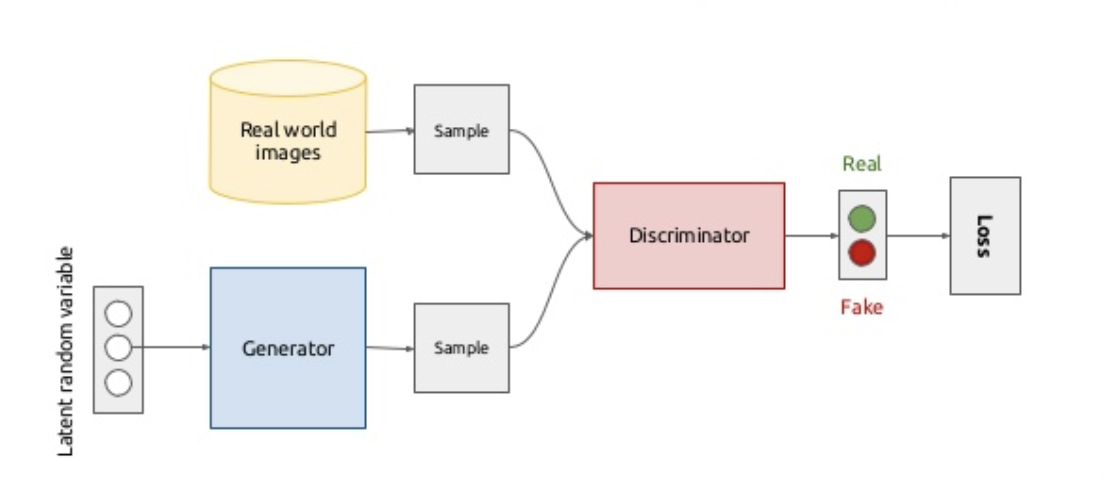
这里其实有个很有趣的前提
Diffusion Model
和GAN基于对抗的思路不同
假设x0是一张真实图像
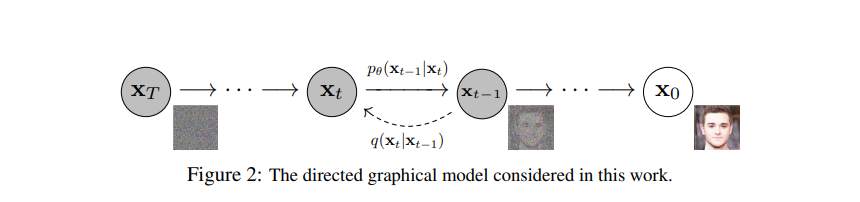
三.怎么用AI实现文字绘画
截止到目前位置
在当前节点它是CLIP
CLIP
CLIP(Contrastive Language–Image Pre-training) 是OpenAI在2021年提出的一个模型
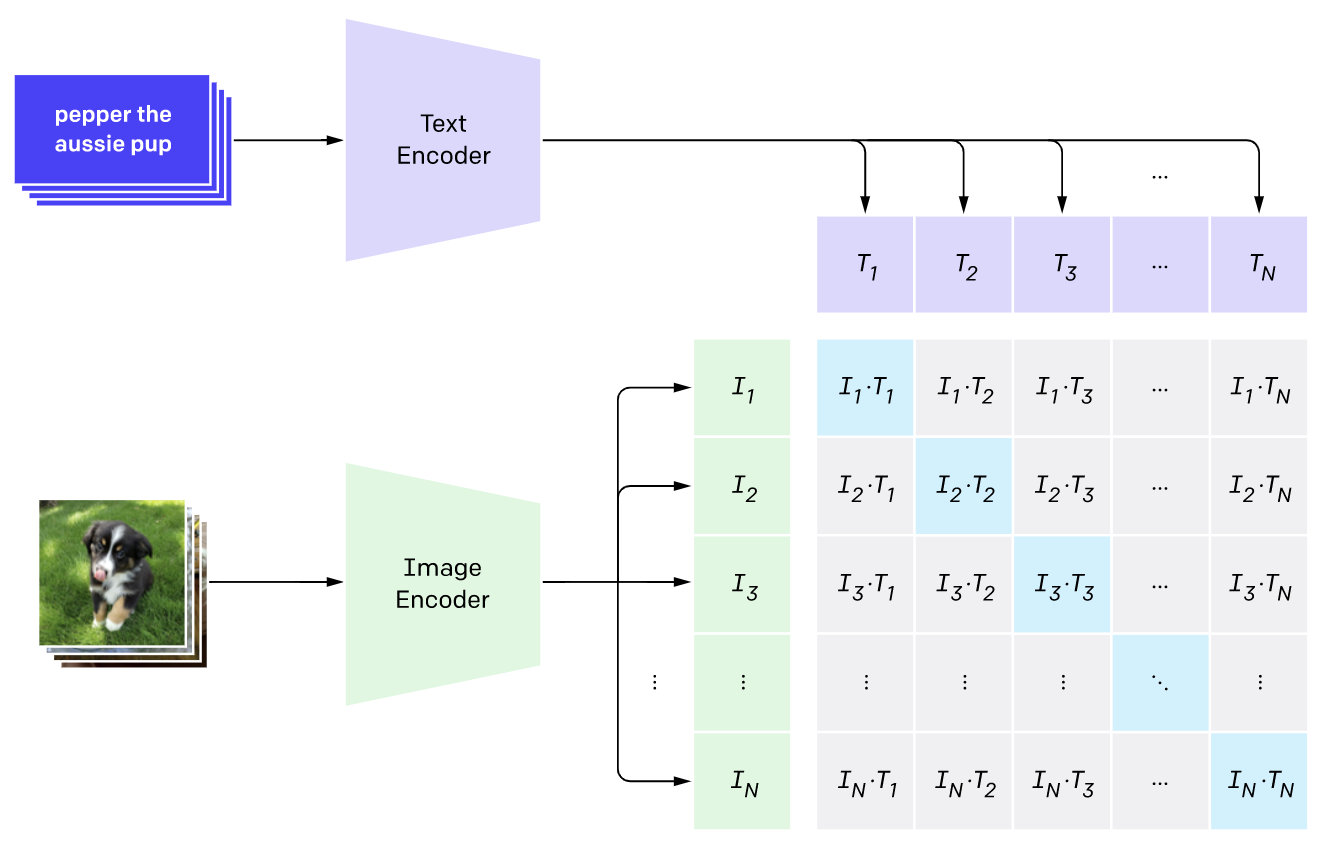
CLIP模型使用分类器来提取图像的标签
终于可以开始画了
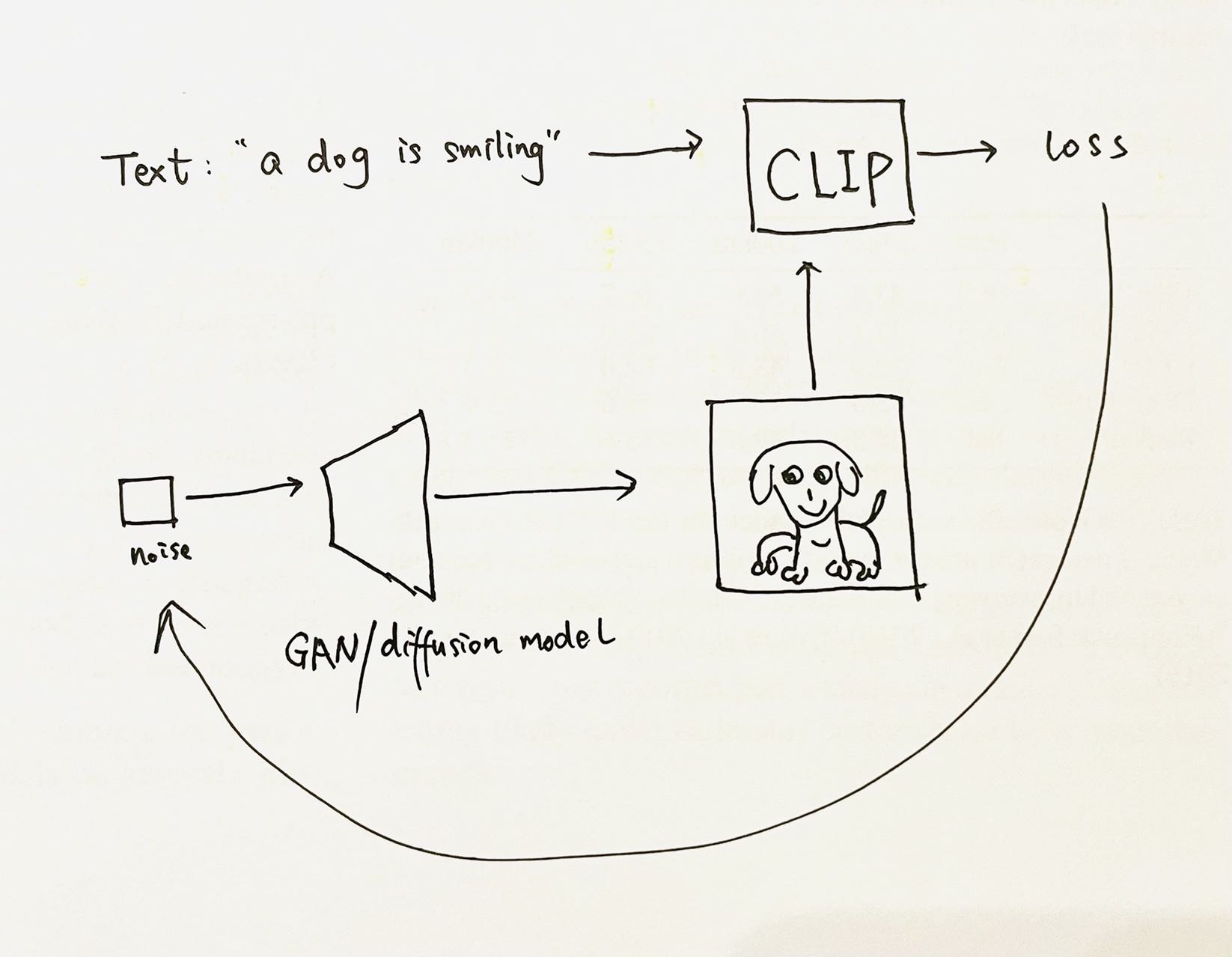
既然可以计算一张任意图片和一句任意文本间的CLIP表征相似度
- 给定一句文本
, 。 - 使用GAN/diffusion模型
, , 。 - 计算(embT, embI)二者的相似度
, , 。
整个过程不需要训练任何模型
结尾
附上一些我改装的disco diffusion(模型是guided diffusion + CLIP)生成不错的效果图
躺在废墟中的玻璃鲸鱼

山随平野尽

五颜六色的立方体冰块漂浮在火山的湖泊中

奇异森林
