Birth, viral success, open-sourcing, plagiarism, and fading away: the journey of a product.
This is a long, long chronicle.
Origins
The story begins on a weekend in May 2022. I was sitting in a bookstore in Beijing, debugging the Disco Diffusion model. At that time, the AI art generation era was just beginning to emerge, and Stable Diffusion had not yet been released. It took 5 minutes to generate a single image on a high-performance V100 GPU.
I encapsulated the open-source code into an interface that only needed to load the model once and exposed few parameters. I rented a GPU for $300 per month and posted on social media: anyone who wanted to try out AI art generation could send me sentence descriptions, and I would run them on the machine and send the generated images back to them.
A friend suggested, “Why not build a website for everyone to use?” So we created 6pen.art. We quickly gained 1 million users, but then gradually faded into obscurity. This “startup” wasn’t very successful, and I felt that not training a differentiated model was a major factor in our failure, but I won’t elaborate on that here. As mentioned earlier, AI art generation was extremely slow before Stable Diffusion was released, and most of my time was spent on model acceleration, with one of the optimization targets being the CLIP model.
CLIP is a model released by OpenAI in 2021 that can compare the similarity between any image and a piece of text. In Disco Diffusion, the model uses CLIP to calculate the loss between the generated image and the user’s prompt, continuously optimizing the loss to achieve the desired image generation.
Sitting in the bookstore, a thought suddenly entered my mind: Since it can compare image-text similarity, could it be used to search photos? After searching, I found that someone had already done this. The principle is to upload photos to the server, extract features uniformly, input English text and calculate the similarity between the text and each image, then sort to achieve image search.
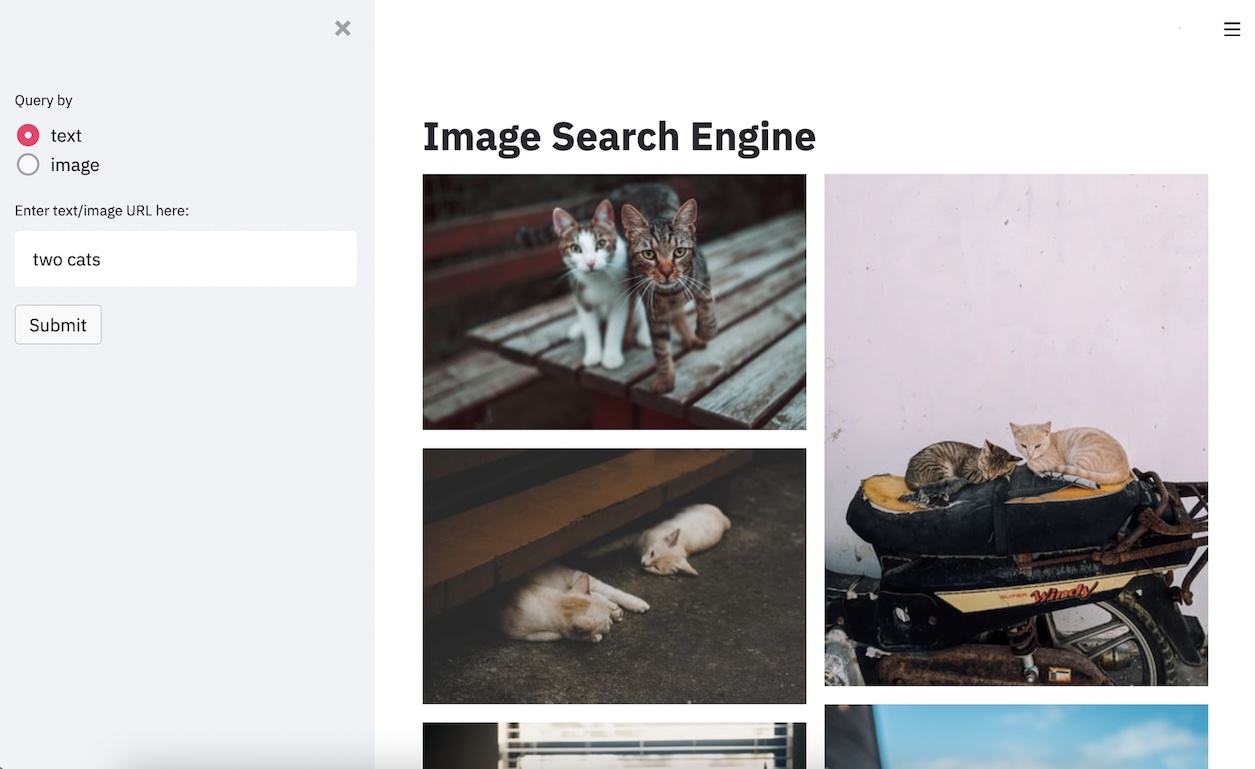
I started experimenting by uploading my iPhone photo album to the server, and after some testing, I found that the results were surprisingly good! It was especially effective when searching for abstract concepts. For example, when I input “lonely”, it returned these top three photos:

Storing photos on a server isn’t a good idea. The place where I have the most photos is my local iPhone photo album. Would it be possible to create a CLIP image search app that runs entirely locally? I really liked this idea and discussed it with friends several times, but each time it came to nothing.
I was too uncertain:
- I knew nothing about iOS development.
- Apple’s underlying system might not support CLIP model operators.
- Even if it could run, if the indexing speed was slow at 1 second per image, or it took 10 minutes to search, this product would be pointless.
It wasn’t until 2024 that on-device language models started gaining attention, but in 2022, I couldn’t find a single language model running on-device in the App Store. It seemed… unfeasible, right? I finally forgot about it and continued to focus on developing 6pen.
Echo
The turning point came in early December 2022. Due to some changes, I suddenly found myself in a foreign country (South Korea) where I didn’t speak the language, and my journey with 6pen also came to an end. So, in an empty coffee shop, I sat all day with a laptop and an iced latte. K-pop played in the background, thick snow outside the window, and I ate the shop’s sandwiches when hungry at noon. This was how I spent each day.
The internet speed was incredibly fast here, there was no COVID testing, and the conversations around me automatically became white noise due to the language barrier. I suddenly felt like I was living in a vacuum. This strange sense of isolation excited me: like an exiled fugitive, who I was and my past no longer mattered. Here, I felt like I could learn and accomplish anything from scratch. It was time to start making a product that truly excited me - this idea grabbed hold of me again.
But this time, I was no longer afraid to verify its feasibility. I learned to write tokenizers in Swift, researched how to calculate and store features, and learned to use multi-core acceleration for indexing. I asked many naive questions on StackOverflow and had many moments of frustration. But I kept envisioning this scene: entering “coffee and laptop” on my phone, clicking search, and after a rotating animation, this photo jumping out from 30,000 photos in my album, appearing before my eyes.

This fantasy drove me to work tirelessly for 2 weeks, I forgot to eat lunch several times, drinking a latte until evening when I was starving with stomach pain and feeling weak all over. There was a significant time marker: ChatGPT had just been released then. But I was so deeply involved in development that I completely ignored its existence, which might have been the last few times in my life that I asked questions on StackOverflow.
Anyway, on December 27th, I finally completed the product. I split the text model and image model in CLIP into two separate models, loading them separately:
When building index for the photo album, only load the image encoder, calculate the index and save it. When searching, only load the text encoder, and calculate the cosine distance with the saved index one by one, then return the top K photos with the highest similarity.
Staggered model loading can effectively reduce the software’s memory usage and accelerate index building. At the same time, using multi-core parallel computation of the index can achieve an indexing speed of 2000 photos/minute on my iPhone 12 mini, and searching 10,000 photos takes less than 1s.
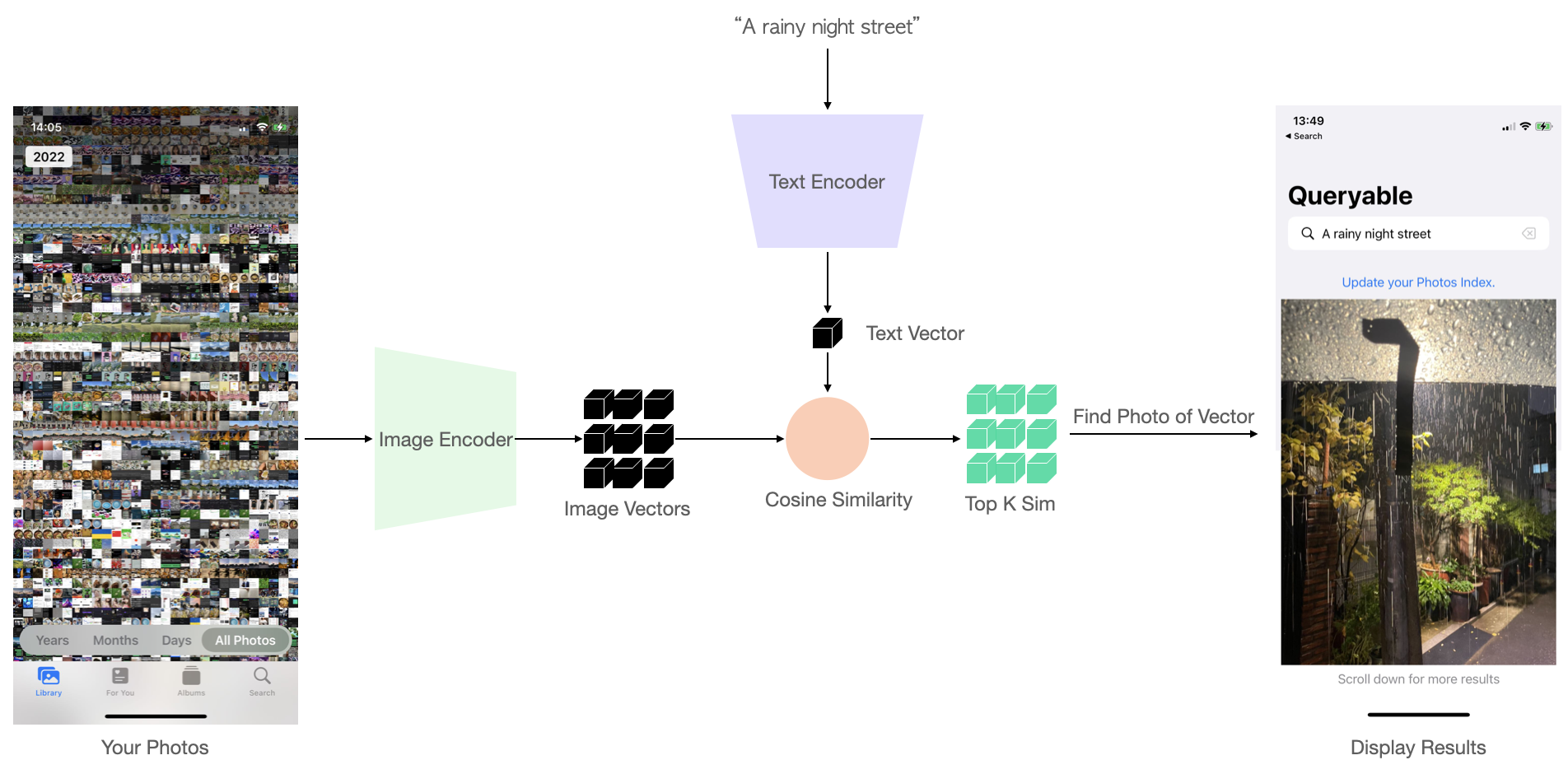
This proved the operators’ support and usable speed. My anxiety finally subsided.
Pricing
As a pricing genius, my idea was:
Users can download for free, build an index, and search at will. When they have new photos in the future and want to update the index, they need to pay.
The brilliance of this strategy is that only those who really use and like the product need to pay. Those who come to try it out, or find it different from their expectations after trying, don’t need to and won’t pay, thus avoiding users paying for nothing and angrily giving bad reviews.
But soon, while debugging the code, I discovered a reasonable but funny fact: In-app purchases require an internet connection. This was like a bolt from the blue, because from the beginning, I was determined: “Never allow the App to pop up an internet request under any circumstances”. Why? Because this is a photo album search application, it will scan your entire photo album, and no one knows whether you will upload the user’s photos to some server on Earth after connecting to the internet. I know I could explain “why there’s a pop-up requesting internet permission” in the product, but I didn’t want to fall into the awkward situation of self-justification.
So I turned it into a paid product: users must purchase it, and then from opening the App, building the index to completing the search, only one “photo album permission request” pops up. I knew this was stupid - subsequent lessons also proved that paid downloads would bring a lot of negative reviews: because the model is so computationally intensive, index building would crash or lag on many devices with small memory, and on the iPhone X series, operator support abnormalities caused all-black search results, all of which would be cursed as “Ripoff”; moreover, users wouldn’t care about the fact that it “doesn’t pop up internet requests”, once the above abnormalities occur, they would delete the App, leave bad reviews, and question where I secretly uploaded their photo albums.
Anyway, I finally priced it at $3.99, one-time purchase, lifetime use.
Pushing to Market
I named the product Queryable, and posted a rather dramatic status: “I think this app might change the world”. I was so confident about this that I even wrote an email to Tim Cook, hoping Apple would acquire this product (laughs). At that time, I had already started using ChatGPT, but maybe because I was too excited, I forgot to replace my own name. After clicking send, I saw that the email started with “Dear Mr. Cook, My name is [Your Name]”.
Of course, I didn’t receive a reply in the end.
I also ambitiously prepared to write an article introducing the product, repeatedly deliberating over words, trying to make it the style of a good Hacker News article in my mind. On December 29th, the day the App Store approved it, I immediately submitted my article link to Hacker News, but the system prompted that “the account is too new to submit”. I emailed them to report this issue and asked a friend to post for me using his account.
The post quickly sank, and I didn’t receive a reply to the email either.
I was disappointed, but due to receiving many user requests to support Chinese input, I didn’t have time to grieve and immediately threw myself into Chinese model training. Thanks to separating the text model and image model in CLIP, I only needed to find Chinese-English bilingual parallel corpus, train a Chinese text model, and align its output with the English model, which is essentially distillation.
Soon, on January 18, 2023, I completed the Chinese version, named “Xunyin” (寻隐, 寻: Seek 隐: Hidden), derived from the ancient poem 寻隐者不遇 by Jia Dao, also implying the meaning of “discovering hidden meanings from the photo album”. After all, my initial shock was realizing that those few photos represented loneliness when I searched for “lonely”.
After launching, I wrote an article in Chinese introducing this product on a Chinese community site called sspai. It actually made it to the homepage of the day, which brought a large number of downloads and $1,500 in revenue.
In early February, I received a reply from a Hacker News editor. He said my account had been mistakenly flagged as SPAM by the system, and encouraged me to repost, saying my article was definitely suitable HN material. He would put the link to my new post in the candidate pool: articles in the pool would randomly enter the bottom of the homepage, and if users upvoted it, the ranking would rise; otherwise, it would sink again.
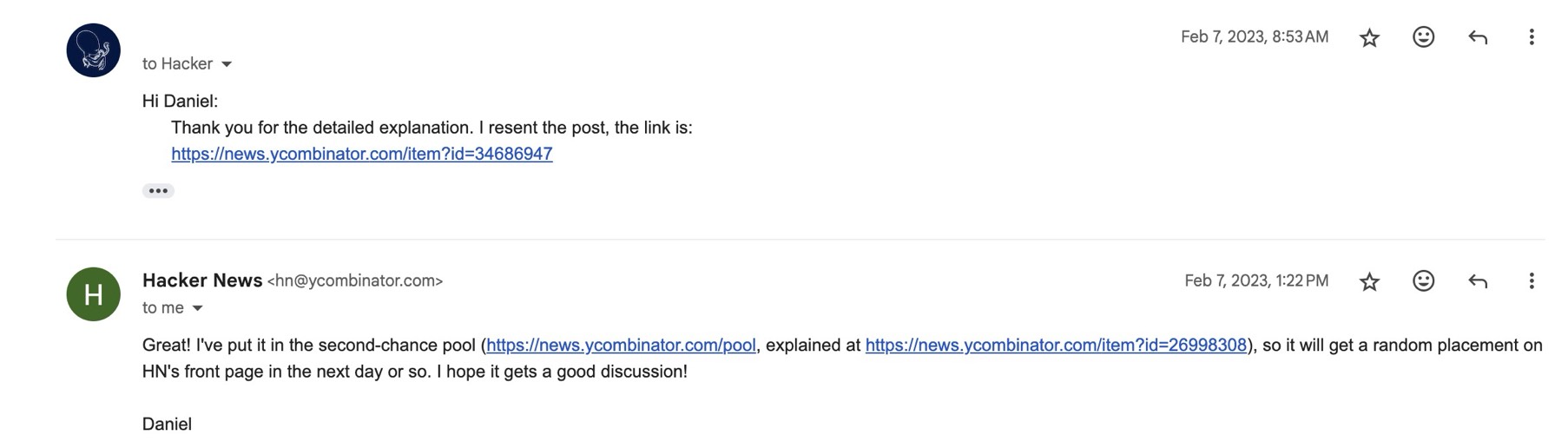
I found the pool mechanism interesting. The community seemed to want to maintain a hacker spirit under a decentralized mechanism:
This is our long-running experiment in story re-upping. Moderators and a small number of reviewer users comb the depths of /newest looking for stories that got overlooked but which the community might find interesting. Those go into a second-chance pool from which stories are randomly selected and lobbed onto the bottom part of the front page. This guarantees them a few minutes of attention. If they don’t interest the community they soon fall off, but if they do, they get upvoted and stay on the front page.
At 7 PM that evening, my post shot to #2 on the Hacker News front page.
That night, I kept refreshing my phone every 10 seconds, the excitement lasting from midnight when I lay down until 3 AM. I was constantly replying to discussions under the post and responding to bug report emails. Someone taught me how to use LSH to improve search speed, someone suggested how to map photo coordinates to cities without internet connection, and others discussed why it failed to run on iPhone X.
This feeling seemed unrelated to how many downloads the product had or how much money it made: you created something, received praise from a large group of peers, excited discussions, and suggestions. It’s a rare experience in life, and once is quite satisfying.
One comment in particular caught my attention:
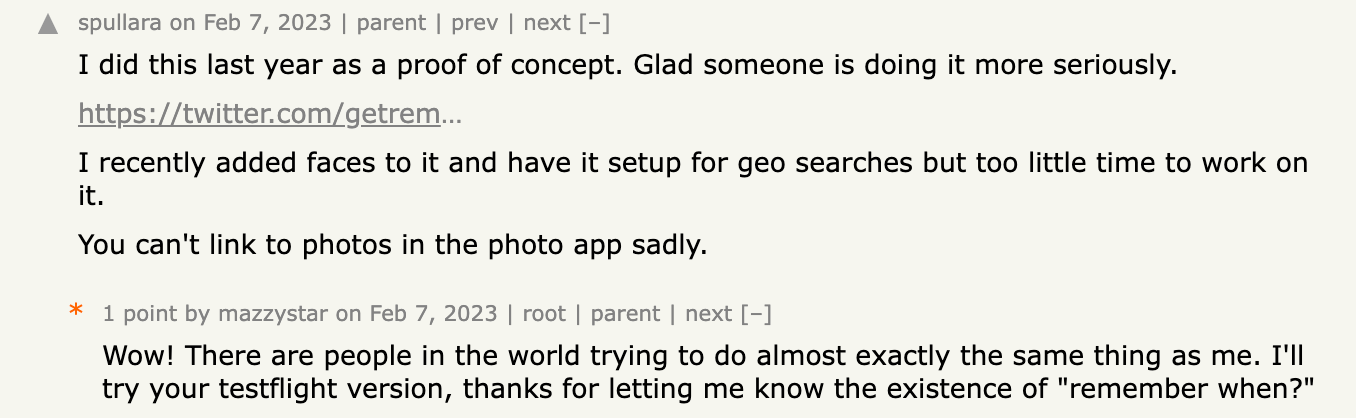
I read the author’s development log and discovered that we were like two minds on Earth randomly generating the same idea. I even tried his yet-to-be-launched product on TestFlight, feeling a strange sense of kinship.
Hacker News is the World’s Bulletin Board
That night, I fell asleep excited, thrilled that my product was liked by my peers. As it turned out, I had greatly underestimated the influence of Hacker News: In just two days, Queryable almost swept the #1 spot on the tools category in all European countries, and #2 in the US, with a total revenue of $2,800. For the next few days, the first thing I did when I woke up was to check Gmail. Germany, France, Spain, the USA, emails came from all directions like snowflakes: some reporting bugs, the magazine from German wanting to cover the story, french iOS communities would like to share the app, YouTuber wanting to review the app. My Twitter would also constantly receive notifications because people were retweeting the Hacker News hot list.
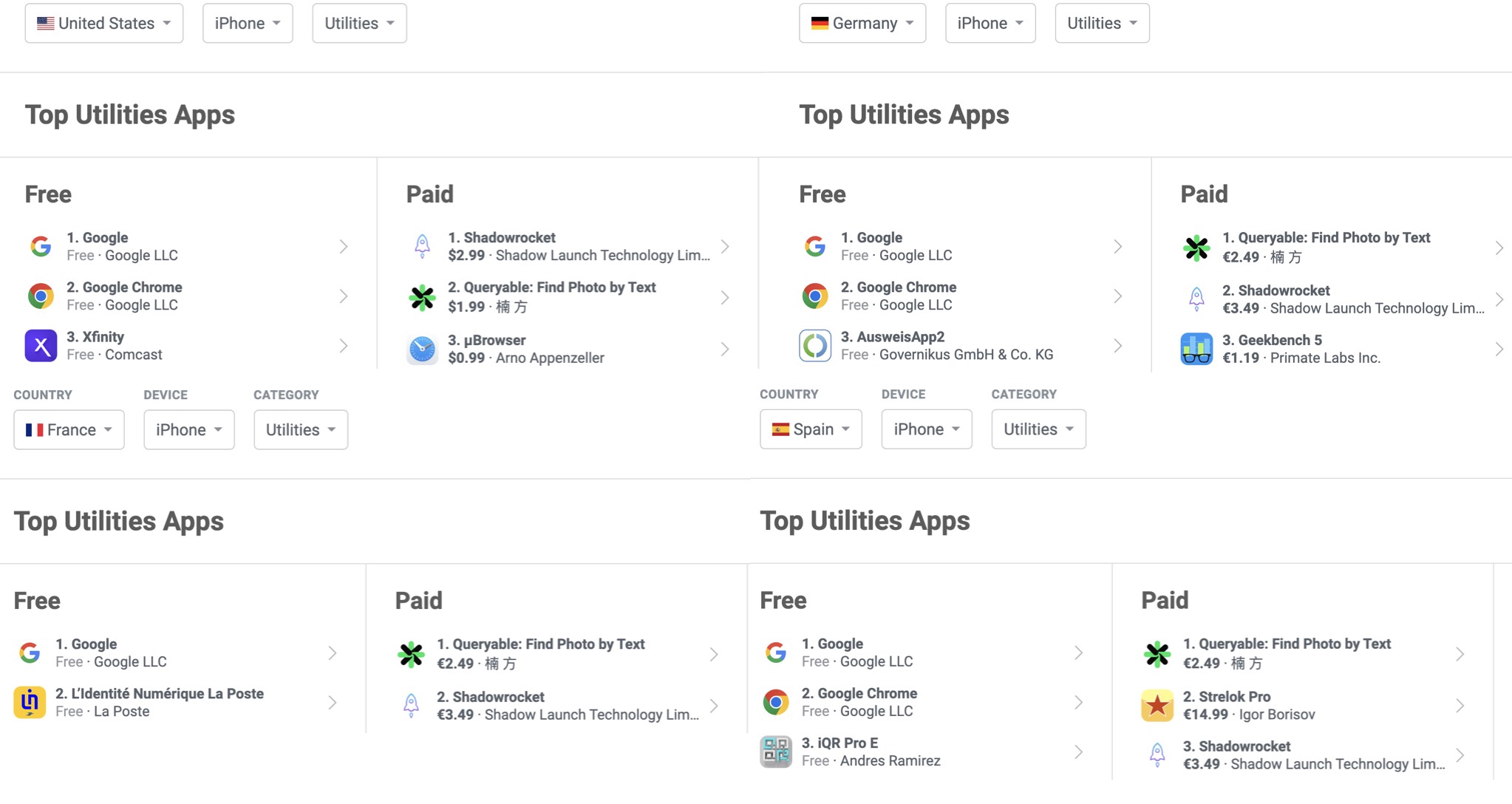
Even a friend working in the Apple Photos team told me that their team knew about Queryable.
All of this forced me to realize a kind of “worldliness”: Hacker News doesn’t just belong to the United States or English-speaking countries; it’s like a virtual bulletin board in the central area of the world. Each work briefly stays on it, but countless eyes from various countries are always watching. This product actually only supports English, but that didn’t prevent it from reaching #1 on the paid tools charts in almost all European countries. They seem to naturally accept products that can only be used in English. Products that work in the US often can be accepted by Europeans as well.
The buzz quickly subsided, followed by many negative reviews.
I didn’t see any comments on Hacker News that made me uncomfortable. However, after secondary dissemination through various websites, YouTube channels, and online communities, less friendly users surfaced. There were mainly two points of attack:
- Fear that I would steal their photo album privacy.
- I am a Chinese developer.
The second point made the situation of the first point worse. After the successive waves of attention from Hacker News ended, the sales of this product in Western markets quickly became dismal, with single-digit downloads and tens of dollars in revenue every day.
In my imagination, something that changes the world is unrivaled, how could it suddenly stop? I fell into great doubt and pessimism.
Free & Open Source
Fortunately, exposure from Chinese domestic social media accounts like Chapingjun (差评) and Guokr (果壳) promoting Xunyin allowed me to earn about $1,500 per month starting from January. And because the model runs on the user’s own device, there were no server costs.
From April onwards, without any traffic exposure and without any updates, I could earn an average of about $400 per month.
But! I still thought this was a very useful product, I just couldn’t let many people know about it. I had a limited-time free promotion once, and the downloads that day exceeded the past daily average by 100 times. I thought, rather than maintaining this income of $400 per month, which might prevent 99% of people from discovering this product, why not let everyone use it, so I decided to make it free forever.
Since it was now free, the source code didn’t seem to be a secret anymore, and I was considering whether to release it. Finally, on July 10, 2023, I made it free and open source. Many people regard “open source” with awe and apprehension, but for me, the motivation for open sourcing was simple:
- I had received numerous emails from developers worldwide inquiring about Queryable/Xunyin’s technical details. Rather than explaining individually, open sourcing would allow them to understand the details directly from the source code.
- Open sourcing could dispel many people’s concerns about photo album privacy.
- I’m not skilled at Swift development, and I believe I had already completed the part of this product that I was most interested in doing. However, I kept receiving emails from users hoping to add features like multi-select deletion, left and right swipe, Mac/NAS/Android support, etc. I wanted to leverage the power of the community, allowing capable developers to refine the product further.
Indeed, after open-sourcing, some people were inspired to create Android(#12) and Mac versions.
Open-sourcing this project also made it to GitHub Trending, and I got a free year of GitHub Copilot because of it, which made me happy.
Plagiarism and Repackaging
Before talking about plagiarism, I want to define what plagiarism is:
Plagiarism refers to the direct or indirect use of others’ works, ideas, or content without authorization, presenting it as one’s own work or idea.
Actually, plagiarism appeared even before open sourcing. Someone made an Android version and released it on Google Play, completely copying the name and product description of Queryable. I felt angry, but this actually requires mastery of both machine learning and iOS development. Before open sourcing, I only encountered one such person.
But after open-sourcing, there were many more copycats and repackagers. As the project has an MIT open-source license, even when they repackaged it with a different icon and re-launched it on the App Store, I felt a bit speechless but wouldn’t say anything. These were the most common cases I saw.
More malicious ones use the Queryable name to repackage and launch, like the one below, with a free + ad revenue model. I’m very worried that users might mistakenly think this is the Android version of Queryable and come to me with problems later.
I would feel sad at first, but when there are too many lice, you stop itching, and later I gradually became indifferent.
Becoming Paid Again
It became paid again in November 2023. Besides the increased income pressure, I found that:
Open sourcing didn’t help my product become better.
I originally hoped that by making it open source and free, professional mobile developers would contribute code to help polish Queryable/Xunyin. But the reality is that those developers who created new apps with better UIs and functionality never sent PRs to my repo. As a result, my product stagnated, and because it was free, I received even more complaints from users than before.
Whenever users emailed me with feedback/bugs, my first reaction was impatience (internally: It’s good enough that I let you use it for free, and you’re still picky). I found that this mindset led to the product falling further and further behind, until one day it would be eliminated.
But once it’s paid, I would calmly deal with users’ opinions and improve the product. My first reaction to receiving feedback is gratitude rather than annoyance. This would force me to inevitably spend effort optimizing the product, ultimately letting all users who have paid use a better-polished product, rather than neglecting maintenance and dying in a few years.
Epilogue
Apple finally announced at this year’s WWDC that iOS 18 will support semantic search for photos, although I still can’t use it in the latest iOS 18 beta, there’s reason to believe Apple will do better than Queryable.
It’s been almost two years since the idea was born and the product was launched. It has accompanied me through life’s ups and downs and witnessed the closure of several coffee shops. I’ve also accompanied it through its birth, peak, and low tide. It hasn’t made money as I initially fantasized (If 1 million people download it and each gives me $1, I would…).
Life goes on, and the story isn’t over yet: Last week, I researched the latest paper and redesigned and trained the Chinese text model. The app size was reduced from 232MB to 159MB, indexing speed doubled, accuracy improved, and the training process took 3 days and cost $70.
Moreover, the recently subscribed Claude 3.5 Sonnet’s code writing ability is incredibly powerful. The “multi-select deletion” feature that I couldn’t manage with GPT-4 before was finally developed and launched last week after a year and a half delay. I quite like this calm ending.
I can’t wait to start the next idea that will keep me up all night, the next exile into a vacuum.