TL;DR: This piece delves into my personal experience with an information access crisis and my reflections on developing Sublink, a platform dedicated to link-sharing.
At my previous job, we had a company forum where you could create discussion groups and post within them. Interested people could join these groups and contribute. I created a group called “Knew” with this introduction:
This is a project aimed at ‘brain-sharing’: every week, you can share the latest events and developments in your areas of interest with everyone. This way, we can all share our brains with each other. You don’t need to have “even the slightest” professional background in what you’re sharing; simply making others aware of its existence is already meaningful enough.

Each week, I’d share new discoveries in the group. I shared about DALLE-2, Azuki, vaccine efficacy data, and more. After just two posts, my group’s popularity had already reached the forum’s top three, with many subscribers and likes.
However, no one else was sharing; they were merely consumers. After the third or fourth edition, I gave up. “Creating a channel and getting many people to cheer for me” wasn’t my original intention; I couldn’t access other people’s brains.
I began to ponder if there was a way to make information sharing between people easier and less pressured. In September this year, I came up with the idea of “link collections”:
You could create a collection for anything you like and share it with friends. When you make a new discovery, you add the link to this collection, and your friends can see it.
In late August, I shared this idea with two frontend developer friends: one from France, whom I met through the Queryable project, and another from ByteDance. They both showed great interest, but they were extremely busy. Until early November, progress on this product was almost at a standstill.
Left with no choice, I had to learn from scratch: In 2023, Next.js + Typescript + Prisma + Supabase seemed to me the best path for learning full-stack development from zero. I spent the entire month of November learning React State and Next.js App Router with the help of YouTube, and by late November, I had nearly grasped the basics.
Then came two weeks of development. Yesterday, I finally launched the website: In simple terms, you can use it to organize interesting movies, articles, and videos you come across daily, then share them with your friends. Oh, and it also supports RSS: when you add new links, people who subscribe to your Collection using any RSS client will receive notifications.
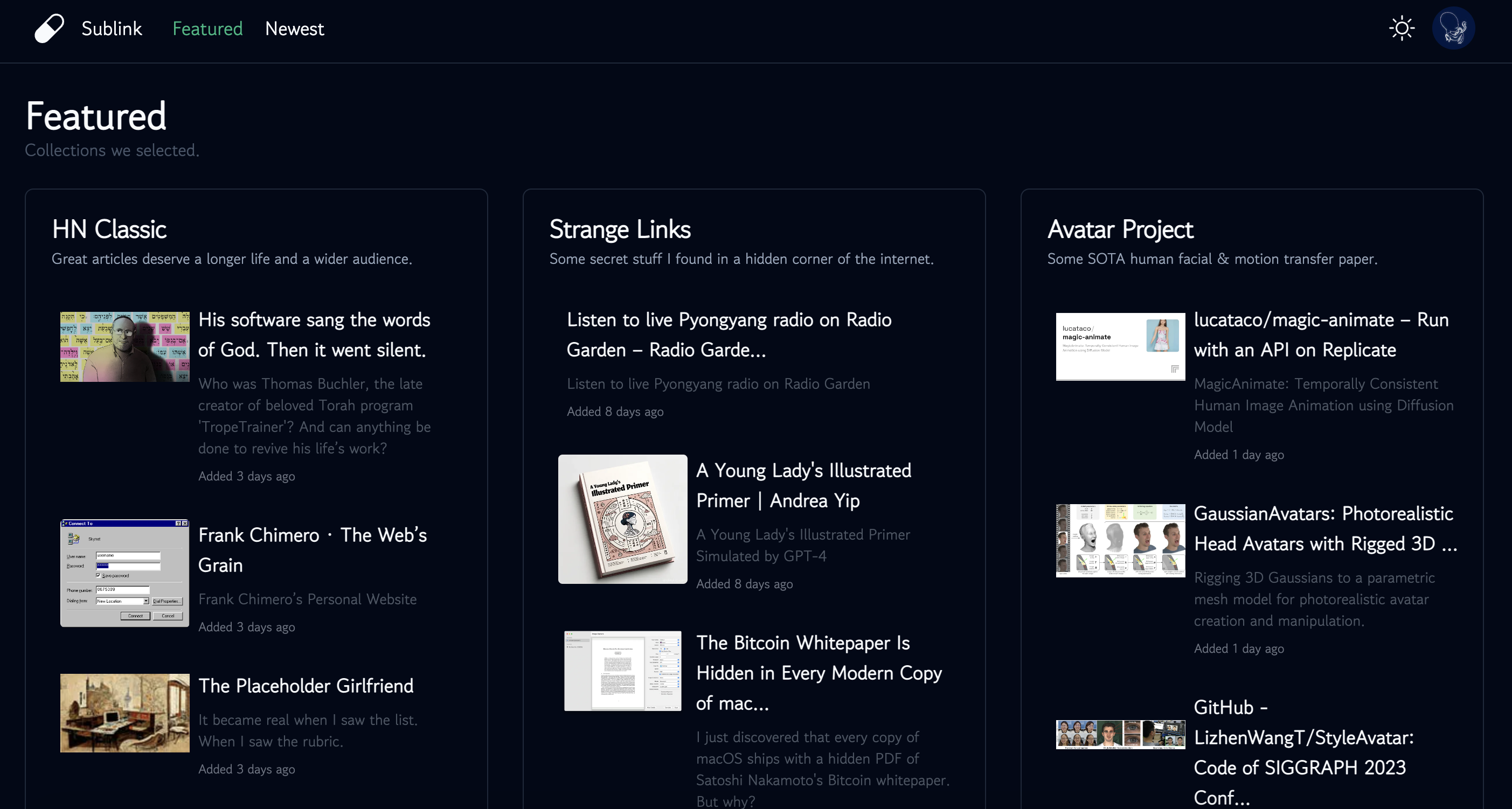
But the question remains: What’s it good for?
The Small Website Discoverability Crisis
I’m a fan of Radio Garden, where I can even listen to live radio from Pyongyang. I also love Neal’s password games. The internet hosts a myriad of shiny, intriguing, and unique sites, yet there’s no dedicated place to store and showcase them. Whenever I read a good blog, I share the link with multiple friends, discuss it with them, and then forget about it. Last week, I saw a trending article on Hacker News: The Small Website Discoverability Crisis which coined this term.
Search engines based on the Page Rank algorithm have led to the rise of content farms and link farms. Content farms are websites that generate large amounts of irrelevant content using AI or scripts to improve their keyword rankings in Google searches. Link farms involve mutual backlinking between website owners or purchasing backlinks to boost a site’s PR ranking.
All of this results in truly valuable websites becoming dead zones in search engines.
Information Cocoon Rooms
We’re surrounded by recommendation algorithms. Sure, we can ask GPT for new knowledge, but “you can’t ask about something you don’t know exists.” So even with the world’s most knowledgeable teacher, if we can’t generate new questions that break through our own cognition, it’s hard to get answers that open our horizons. For instance, do you know about the Aronson Effect?
That’s why, in the age of LLMs, there’s a greater need for human-curated subscription content, allowing information not filtered by neural networks to enter my brain in unfamiliar, raw, and uncomfortable ways. This certainly isn’t something most people need, but I guess I’m not the only one who does.
Adding LLM?
If this product were made 15 years ago, it wouldn’t be any different. So, at the end of 2023, is it possible to incorporate the currently trending LLM into the website? I thought of two points:
1. Automated Summaries
Initially, I wanted to use LLM to extract webpage descriptions as brief introductions for each Link, but I eventually gave up: LLM charges based on usage, meaning I couldn’t control the monthly costs. When users add a large number of Links, the expense for article summarization could become exorbitant, which is terrifying for a website that clearly can’t turn a profit.
To keep the website running longer, it’s best to minimize uncontrollable expenses as much as possible.
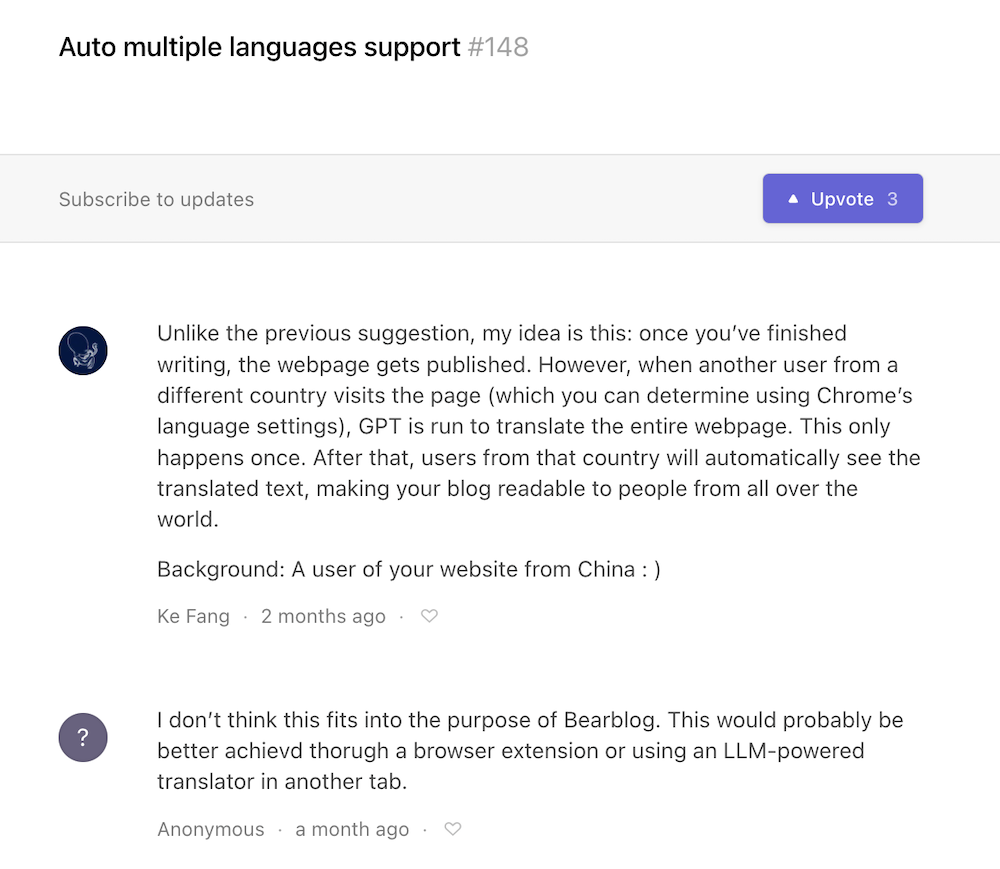
2. Language Delivery Network (LDN)
I once envisioned something, let’s call it a Language CDN: When I write a blog, I want people from different countries and languages worldwide to see a version in their local language. A simple method is to let users use built-in browser translation or install translation plugins, but this might result in the same article being translated many times, not only wasting GPU inference costs but also making it impossible for authors to control translation quality.
This led to the idea of LDN: An author writes a blog or creates a website and can use an LDN platform to host their multilingual versions. Whenever a new language user visits the network, but LDN doesn’t have a cache for that language, it translates once. After that, other users of the same language can use the previously translated cache. Moreover, authors can locally manage the original translation data for multiple languages, thus controlling and adjusting the wording of translations.
I once submitted this as Feedback for the open-source blog system bearblog, but didn’t receive a positive response. Maybe later I’ll try adding this feature to Sublink, but only if people are willing to create original articles on Sublink.
Pricing Model
I have no hope that this website will make money, but I want it to live long enough to accumulate as many Links and Collections as possible. So I need to generate some revenue from it.
I’m actually a bit confused: Is the core of Sublink about “subscribing to quality collections” or “a personal link collection organization tool”? This divergence leads to two different logics. The former would have other people’s Collections on the homepage, while the latter would have an input box. The former relies on high-quality content, which is difficult in the early stages.
This divergence leads to differences in the payment model: Charging for collection subscriptions isn’t impossible, but it’s almost impractical. If we follow the tool logic, it’s more like Notion’s approach, with a higher possibility of monetization, but then the value of “letting more people see excellent links” would no longer exist.
I’m stuck here now, which is why I haven’t implemented any payment system at all. Perhaps later I can gain more insights from user behavior and feedback.
That’s all my thoughts on creating Sublink. I’m also a Sublink user myself (that’s why I created it). I’ll put a list of articles I’ve read and found good here. You can log in and subscribe, or use any RSS client to subscribe to this list. When I add new links, you’ll see them. You can also turn your favorite videos, movies, books, webpages, or anything with a link into collections and share them with friends.
Perhaps this is my small, insignificant act of resistance against a world about to be engulfed by GPT-generated content.